![]()
RNN for vattenfall by Colab#
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from pandas.plotting import register_matplotlib_converters
# plt.style.use(['science','no-latex'])
# plt.rcParams["font.family"] = "Times New Roman"
%load_ext autoreload
%autoreload 2
import tensorflow as tf
from google.colab import drive
drive.mount('/content/drive')
Mounted at /content/drive
1, Load the data#
from tensorflow import keras
from google.colab import drive
drive.mount('/content/drive')
df = pd.read_csv('/content/drive/MyDrive/Data/vattenfall_turbine.csv')
#drive.flush_and_unmount()
#print('NB: Unmount the google cloud driver')
import numpy as np
#df = pd.read_csv('vattenfall_turbine.csv')
keys = df.keys().values
feature_keys = keys[np.arange(1,5).tolist() + np.arange(7,10).tolist()]
time_key = keys[0]
Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount("/content/drive", force_remount=True).
plot_cols = feature_keys[0:len(feature_keys):2]
plot_features = df[plot_cols]
#plot_features.index = df[time_key]
fig1 = plot_features.plot(subplots=True, figsize=(10, 8))
plt.show()
from IPython.display import display, Markdown
#display(Markdown(' <font size="6"><span style="color:blue">**Lets take a close look at the time series.**</span> </font>'))
display(Markdown('<span style="color:blue;font-size:50px">**Lets take a close look at the time series.**</span>'))
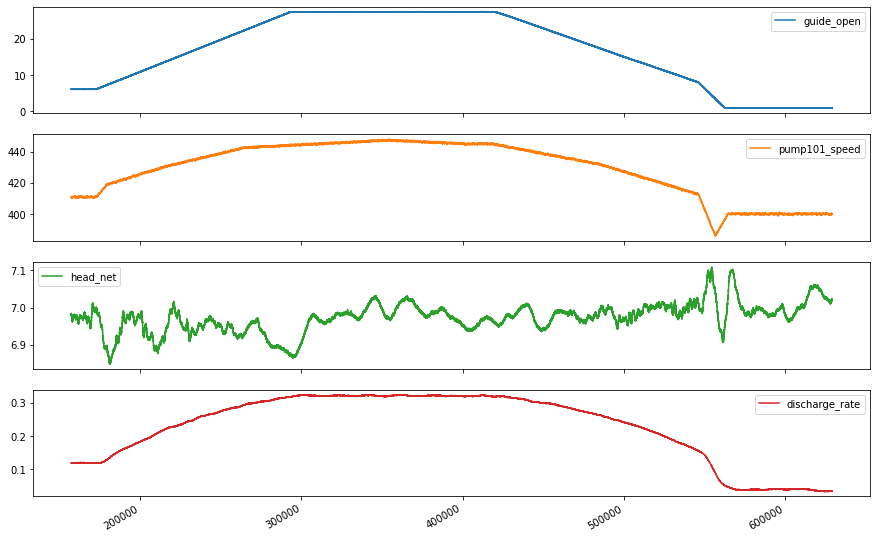
plot_features = df[plot_cols][int(len(df)/5):int(len(df)*4/5):10]
#plot_features.index = df[time_key][:480]
fig2 = plot_features.plot(subplots=True, figsize=(15, 10))
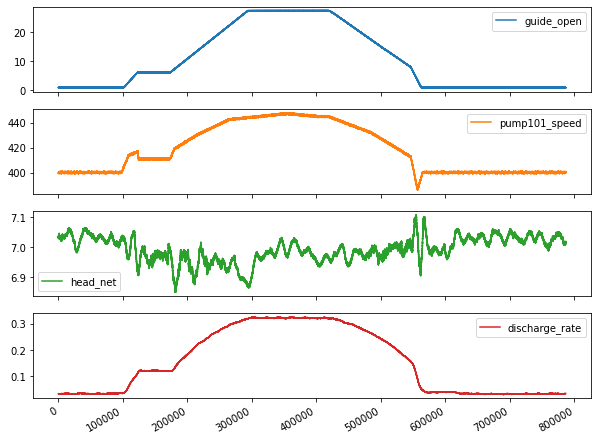
Lets take a close look at the time series.
2, Preprocessing data: normalize, train, validation, test, etc.#
2.1, resample the data with low-resolution#
df_train = df[feature_keys[0:7:2]][int(len(df)*0.2):int(len(df)*0.8):10]
display(Markdown('<span style="color:red; font-size:30px">**No. of the values in the training dataset is: %d**</span>' %len(df_train)))
# plot the data and check their variations along time
df_train.plot(subplots=True, figsize=(15, 10))
plt.show()
#print('No. of the values in the training dataset is: %d' %len(df_train))
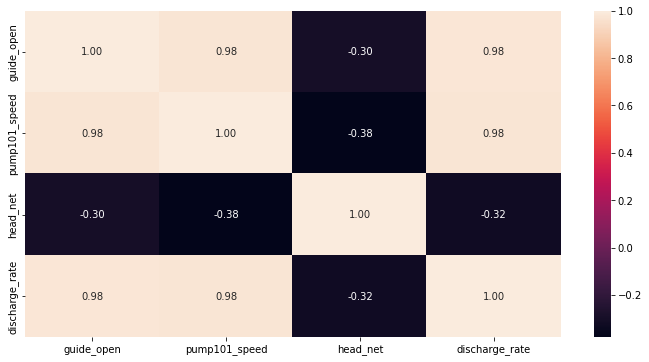
display(Markdown('<span style="color:blue; font-size:20px">**Plot the heatmap for variation of standard deviation**</span>'))
# check he correlation
import seaborn as sns
plt.figure(figsize=(12, 6))
sns.heatmap(df_train.corr(), annot=True, fmt=".2f")
plt.show()
No. of the values in the training dataset is: 47186
Plot the heatmap for variation of standard deviation
2.2, normalize the data#
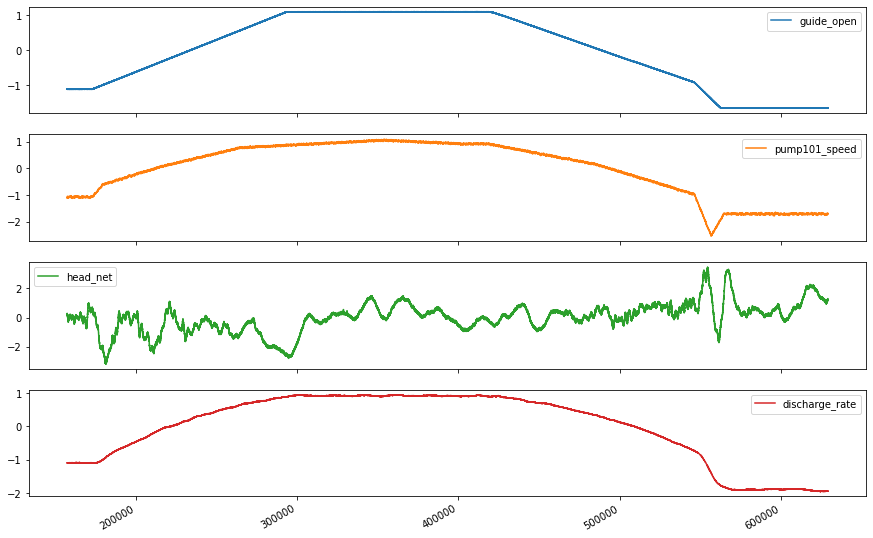
# First, we assume all data are used for the training (the time series is not that stationary for the prediction)
df_train_mean = df_train.mean()
df_train_std = df_train.std()
train_df = (df_train-df_train_mean) / df_train_std
fig2 = train_df.plot(subplots=True,figsize=(15,10))
# Second, plot the standand deviation of features within this dataframe
df_std = train_df.melt(var_name='Column', value_name='Normalized')
plt.figure(figsize=(12, 6))
ax = sns.violinplot(x='Column', y='Normalized', data=df_std)
fig3 = ax.set_xticklabels(train_df.keys(), rotation=90)

Test the functions of the tf.data.Dataset for slice data to formulate rolling windowed dataset#
df_train = df_train.reset_index(drop=True)
split_fraction = 0.8
train_split, int(df_train.shape[0]*split_fraction)
past = 1000
future = 100
step = 10
learning_rate = 0.01
batch_size = 50
epochs = 10
train_data = df_train.loc[0:train_split-1]
val_data = df_train.loc[train_split:]
# Prepare training dataset
start = past + future
end = start + train_split
x_train = train_data.values
y_train = train_data.iloc[start:end]['head_net'].values
Y_train = y_train[:, np.newaxis]
sequence_length = int(past/step)
dataset_train = tf.keras.preprocessing.timeseries_dataset_from_array(
x_train,
y_train,
sequence_length = sequence_length,
batch_size = batch_size,
)
# Prepare validation dataset
x_end = len(val_data) - past - future
label_start = train_split + past + future
x_val = val_data.iloc[:x_end].values
y_val = val_data.loc[label_start:]['head_net'].values
y_val = y_val[:, np.newaxis]
dataset_val = tf.keras.preprocessing.timeseries_dataset_from_array(
x_val,
y_val,
sequence_length = sequence_length,
batch_size = batch_size,
)
# Print the dimension of the inputs and targets
for batch in dataset_train.take(1):
inputs, targets = batch
print(inputs.numpy().shape)
print(targets.numpy().shape)
# Construct the model
inputs = keras.layers.Input(shape=(inputs.shape[1], inputs.shape[2]))
lstm_out = keras.layers.LSTM(32)(inputs)
outputs = keras.layers.Dense(1)(lstm_out)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile(optimizer=keras.optimizers.Adam(learning_rate=learning_rate), loss="mse")
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 100, 4)] 0
_________________________________________________________________
lstm (LSTM) (None, 32) 4736
_________________________________________________________________
dense (Dense) (None, 1) 33
=================================================================
Total params: 4,769
Trainable params: 4,769
Non-trainable params: 0
_________________________________________________________________
# Estimate the LSTM model
path_checkpoint = "model_checkpoint.h5"
es_callback = keras.callbacks.EarlyStopping(monitor="val_loss", min_delta=0, patience=5)
modelckpt_callback = keras.callbacks.ModelCheckpoint(
monitor="val_loss",
filepath=path_checkpoint,
verbose=1,
save_weights_only=True,
save_best_only=True,
)
history = model.fit(
dataset_train,
epochs=epochs,
validation_data=dataset_val,
callbacks=[es_callback, modelckpt_callback],
)
Epoch 1/10
733/733 [==============================] - 24s 24ms/step - loss: 1.2348 - val_loss: 0.0016
Epoch 00001: val_loss improved from inf to 0.00163, saving model to model_checkpoint.h5
Epoch 2/10
733/733 [==============================] - 18s 24ms/step - loss: 8.8830e-04 - val_loss: 0.0018
Epoch 00002: val_loss did not improve from 0.00163
Epoch 3/10
733/733 [==============================] - 18s 24ms/step - loss: 7.2481e-04 - val_loss: 0.0020
Epoch 00003: val_loss did not improve from 0.00163
Epoch 4/10
733/733 [==============================] - 18s 24ms/step - loss: 5.2729e-04 - val_loss: 0.0022
Epoch 00004: val_loss did not improve from 0.00163
Epoch 5/10
733/733 [==============================] - 18s 24ms/step - loss: 3.5562e-04 - val_loss: 0.0023
Epoch 00005: val_loss did not improve from 0.00163
Epoch 6/10
733/733 [==============================] - 17s 24ms/step - loss: 2.2479e-04 - val_loss: 0.0023
Epoch 00006: val_loss did not improve from 0.00163
! nvcc --version
! /opt/bin/nvidia-smi
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2020 NVIDIA Corporation
Built on Mon_Oct_12_20:09:46_PDT_2020
Cuda compilation tools, release 11.1, V11.1.105
Build cuda_11.1.TC455_06.29190527_0
Sun Oct 17 17:49:11 2021
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla K80 Off | 00000000:00:04.0 Off | 0 |
| N/A 58C P0 59W / 149W | 237MiB / 11441MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
+-----------------------------------------------------------------------------+
# Visualize the results
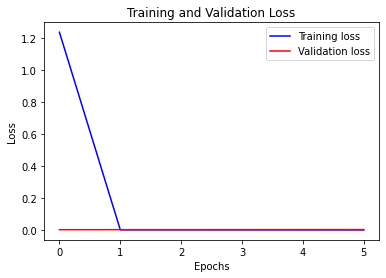
def visualize_loss(history, title):
loss = history.history["loss"]
val_loss = history.history["val_loss"]
epochs = range(len(loss))
plt.figure()
plt.plot(epochs, loss, "b", label="Training loss")
plt.plot(epochs, val_loss, "r", label="Validation loss")
plt.title(title)
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
plt.show()
visualize_loss(history, "Training and Validation Loss")
# Prediciton
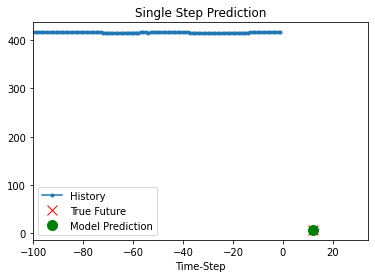
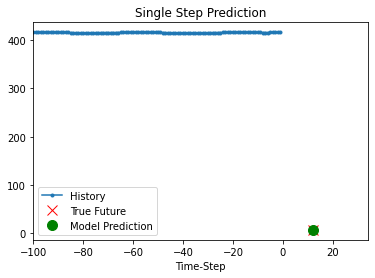
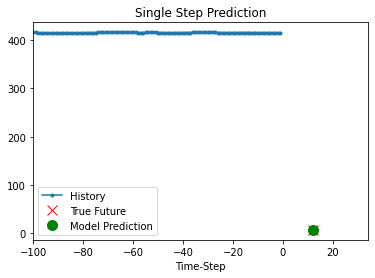
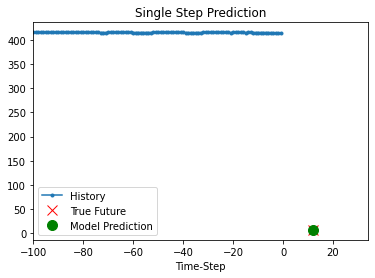
def show_plot(plot_data, delta, title):
labels = ["History", "True Future", "Model Prediction"]
marker = [".-", "rx", "go"]
time_steps = list(range(-(plot_data[0].shape[0]), 0))
if delta:
future = delta
else:
future = 0
plt.title(title)
for i, val in enumerate(plot_data):
if i:
plt.plot(future, plot_data[i], marker[i], markersize=10, label=labels[i])
else:
plt.plot(time_steps, plot_data[i].flatten(), marker[i], label=labels[i])
plt.legend()
plt.xlim([time_steps[0], (future + 5) * 2])
plt.xlabel("Time-Step")
plt.show()
return
for x, y in dataset_val.take(5):
show_plot(
[x[0][:, 1].numpy(), y[0].numpy(), model.predict(x)[0]],
12,
"Single Step Prediction",
)